

I originally posted this at http://blogs.sun.com/brendan/entry/performance_testing_the_7000_series3.
For performance testing storage products, in particular the Sun Storage 7000 series, I previously posted the top 10 suggestions for performance testing, and the little stuff to check. Here I'll post load generation scripts I've been using to measure the limits of the Sun Storage 7410 (people have been asking for these.)
Load Generation Scripts
Many storage benchmark tools exist, including FileBench which can apply sophisticated workloads and report various statistics. However, the performance limit testing I've blogged about has not involved sophisticated workloads at all – I've tested sequential and random I/O to find the limits of throughput and IOPS. This is like finding out a car's top speed and its 0-60 mph time – simple and useful metrics, but aren't sophisticated such as finding out its best lap time at Laguna Seca Raceway. While a lap time would be a more comprehensive test of a car's performance, the simple metrics can be a better measure of specific abilities, with fewer external factors to interfere with the result. A lap time will be more affected by the driver's ability and weather conditions, for example, unlike top speed alone.
The scripts that follow are very simple, as all they need to do is generate load. They don't generate a specific level of load or measure the performance of that load, they just apply load as fast as they can. Measurements are taken on the target, which can be a more reliable way of measuring what actually happened (past the client caches.) For anything more complex, reach for a real benchmarking tool.
Random Reads
This is my randread.pl script, which takes a filename as an argument:
#!/usr/bin/perl -w
#
# randread.pl - randomly read over specified file.
use strict;
my $IOSIZE = 8192; # size of I/O, bytes
my $QUANTA = $IOSIZE; # seek granularity, bytes
die "USAGE: randread.pl filename\n" if @ARGV != 1 or not -e $ARGV[0];
my $file = $ARGV[0];
my $span = -s $file; # span to randomly read, bytes
my $junk;
open FILE, "$file" or die "ERROR: reading $file: $!\n";
while (1) {
seek(FILE, int(rand($span / $QUANTA)) * $QUANTA, 0);
sysread(FILE, $junk, $IOSIZE);
}
close FILE;
Dead simple. Tune $IOSIZE to the I/O size desired. This is designed to run over NFS or CIFS, so the program will spend most of its time waiting for network responses, not chewing over its own code, and so Perl works just fine. Rewriting this in C isn't going to make it much faster, but it may be fun to try and see for yourself (be careful with the resolution of rand(), which may not have the granularity to span files bigger than 2^32 bytes.)
To run randread.pl, create a file for it to work on, eg:
# dd if=/dev/zero of=10g-file1 bs=1024k count=10k
which is also how I create simple sequential write workloads. Then run it:
# ./randread.pl 10g-file1 &
Sequential Reads
This is my seqread.pl script, which is similar to randread.pl:
#!/usr/bin/perl -w
#
# seqread.pl - sequentially read through a file, and repeat.
use strict;
my $IOSIZE = 1024 * 1024; # size of I/O, bytes
die "USAGE: seqread.pl filename\n" if @ARGV != 1 or not -e $ARGV[0];
my $file = $ARGV[0];
my $junk;
open FILE, "$file" or die "ERROR: reading $file: $!\n";
while (1) {
my $bytes = sysread(FILE, $junk, $IOSIZE);
if (!(defined $bytes) or $bytes != $IOSIZE) {
seek(FILE, 0, 0);
}
}
close FILE;
Once it reaches the end of a file, it loops back to the start.
Client Management Script
To test the limits of your storage target, you'll want to run these scripts on a bunch of clients, ten or more. This is possible with some simple shell scripting. Start by setting up ssh (or rsh) so that a master server (your desktop) can login to all the clients as root without prompting for a password (ssh-keygen, /.ssh/authorized_keys ...). My clients are named dace-0 through to dace-9, and after setting up the ssh keys the following succeeds without a password prompt:
# ssh root@dace-0 uname -a SunOS dace-0 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc
Since I have 10 clients, I'll want an easy way to execute commands on them all at the same time, rather than one by one. There are lots of simple ways to do this, here I've created a text file called clientlist with the names of the clients:
# cat clientlist dace-0 dace-1 dace-2 dace-3 dace-4 dace-5 dace-6 dace-7 dace-8 dace-9
which is easy to maintain. Now a script to run commands on all the clients in the list:
#!/usr/bin/ksh
#
# clientrun - execute a command on every host in clientlist.
if (( $# == 0 )); then
print "USAGE: clientrun cmd [args]"
exit 1
fi
for client in $(cat clientlist); do
ssh root@$client "$@" &
done
Testing that this script works by running uname -a on every client:
# ./clientrun uname -a SunOS dace-0 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc SunOS dace-1 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc SunOS dace-2 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc SunOS dace-3 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc SunOS dace-4 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc SunOS dace-5 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc SunOS dace-7 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc SunOS dace-8 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc SunOS dace-6 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc SunOS dace-9 5.11 fishhooks-gate:05/01/08 i86pc i386 i86pc
Great.
Running the Workload
We've got some simple load generation scripts and a way to run them on our client farm. Now to execute a workload on our target server, turbot. To prepare for this:
- Scripts are available to the clients on an NFS share, /net/fw/tools/perf. This makes it easy to adjust the scripts and have the clients run the latest version, rather than installing the scripts one by one on the clients.
- One share is created on the target NFS server for every client (usually more interesting than just using one), and is named the same as the client's hostname (/export/dace-0 etc.)
Creating a directory on the clients to use as a mount point:
# ./clientrun mkdir /test
Mounting the shares with default NFSv3 mount options:
# ./clientrun 'mount -o vers=3 tarpon:/export/`uname -n` /test'
The advantage of using the client's hostname as the share name is that it becomes easy for our clientrun script to have each client mount their own share, by getting the client to call uname -n to construct the share name. (The single forward quotes in that command are necessary.)
Creating files for our workload. The clients have 3 Gbytes of DRAM each, so 10 Gbytes per file will avoid caching all (or most) of the file on the client, since we want our clients to apply load to the NFS server and not hit from their own client cache:
# ./clientrun dd if=/dev/zero of=/test/10g-file1 bs=1024k count=10k
This applys a streaming write workload from 10 clients, one thread (process) per client. While that is happening, it may be interesting to login to the NFS server and see how fast the write is performing (eg, network bytes/sec.)
With the test files created, I can now apply a streaming read workload like so:
# ./clientrun '/net/fw/tools/perf/seqread.pl /test/10g-file1 &'
That will apply a streaming read workload from 10 clients, one thread per client.
Run it multiple times to add more threads, however the client cache is more likely to interfere when trying this (one thread reads what the other just cached); on Solaris you can try adding the mount option forcedirectio to avoid the client cache altogether.
To stop the workload:
# ./clientrun pkill seqread
And to cleanup after testing is completed:
# ./clientrun umount /test
Stepping the Workload
Running one thread per client on 10 clients may not be enough to stress powerful storage servers like the 7000 series. How many do we need to find the limits? An easy way to find out is to step up the workload over time, until the target stops serving any more.
The following runs randread.pl on the clients, starting with one and running another every 60 seconds until ten are running on each client:
# ./clientrun 'for i in 1 2 3 4 5 6 7 8 9 10; do /net/fw/tools/perf/randread.pl /test/10g-file1 & sleep 60; done &' &
This was executed with an I/O size of 4 Kbytes. Our NFS server turbot is a Sun Storage 7410. The results from Analytics on turbot:
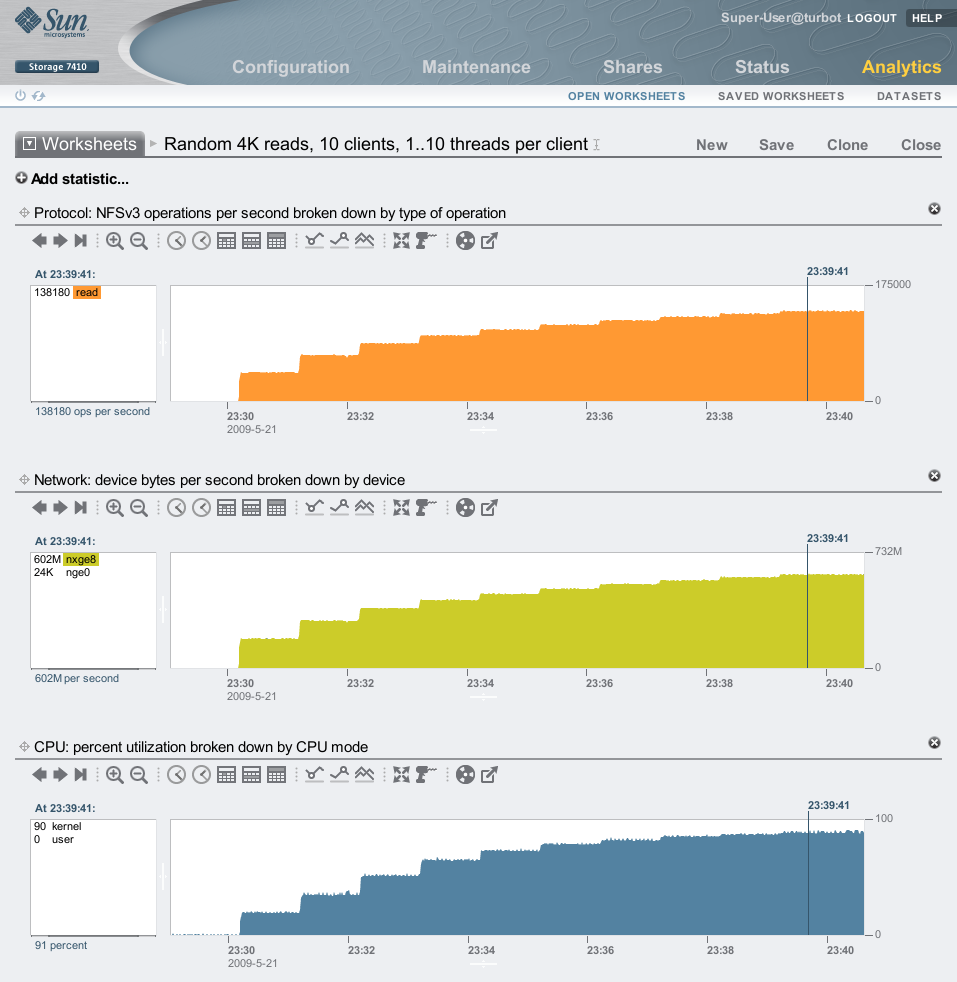
Worked great, and we can see that after 10 threads per client we've pushed the target to 91% CPU utilization, so we are getting close to a limit (in this case, available CPU.) Which is the aim of these type of tests: to drive load until we reach some limit.
I included network bytes/sec in the screenshot as a sanity check; we've reached 138180 x 4 Kbyte NFS reads/sec, which would require at least 540 Mbytes/sec of network throughput; we pushed 602 Mbytes/sec (includes headers.) 138K IOPS is quite a lot. This server has 128 Gbytes of DRAM, so 10 clients with a 10 Gbyte file per client means a 100 Gbyte working set (active data) in total, which has entirerly cached in DRAM on the 7410. If I wanted to test disk performance (cache miss), I can increase the per client filesize to create a working set much larger than the target's DRAM.
This type of testing can be useful to determine how fast a storage server can go – it's top speed. But that's all. For a better test of application performance, reach for a real benchmarking tool, or setup a test environment and run the application with a simulated workload.