

How do companies like Netflix, Google, and Facebook do root cause performance analysis in their cloud environments? These companies use Linux heavily, so are they using SystemTap or another tracer? Netflix is hosted on EC2, how do they do low level CPU profiling, if Xen guests can't access the CPU counters? ... And if these companies don't do these kinds of profiling, aren't they losing millions because of it?
On Thursday it was my privilege to speak again at Surge, the scalability and performance conference. My talk was titled From Clouds to Roots, and showed how Neflix does root cause performance analysis, and answers these questions and more. The slides are on slideshare:
And the video is on youtube:
For background, I began by explaining the Netflix fault-tolerant architecture: how this can automatically work around performance issues, and what kinds of new issues this can introduce. Then I summarized key cloud-wide performance tools, and how we use these to isolate issues to an instance. And finally instance analysis, with the low-level tools we run to find the root cause.
Summary of cloud-wide performance tools:
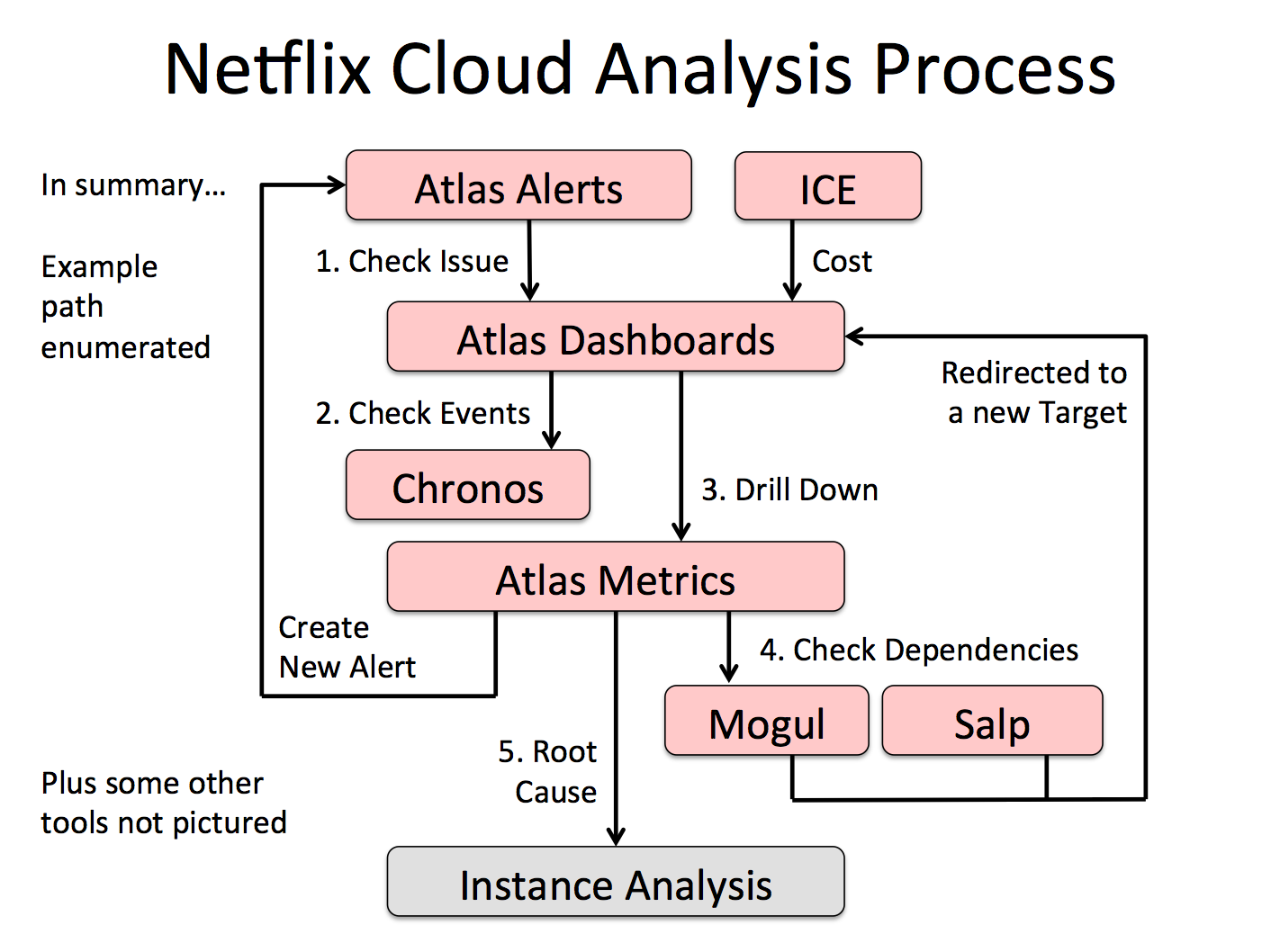
Summary of instance performance tools:
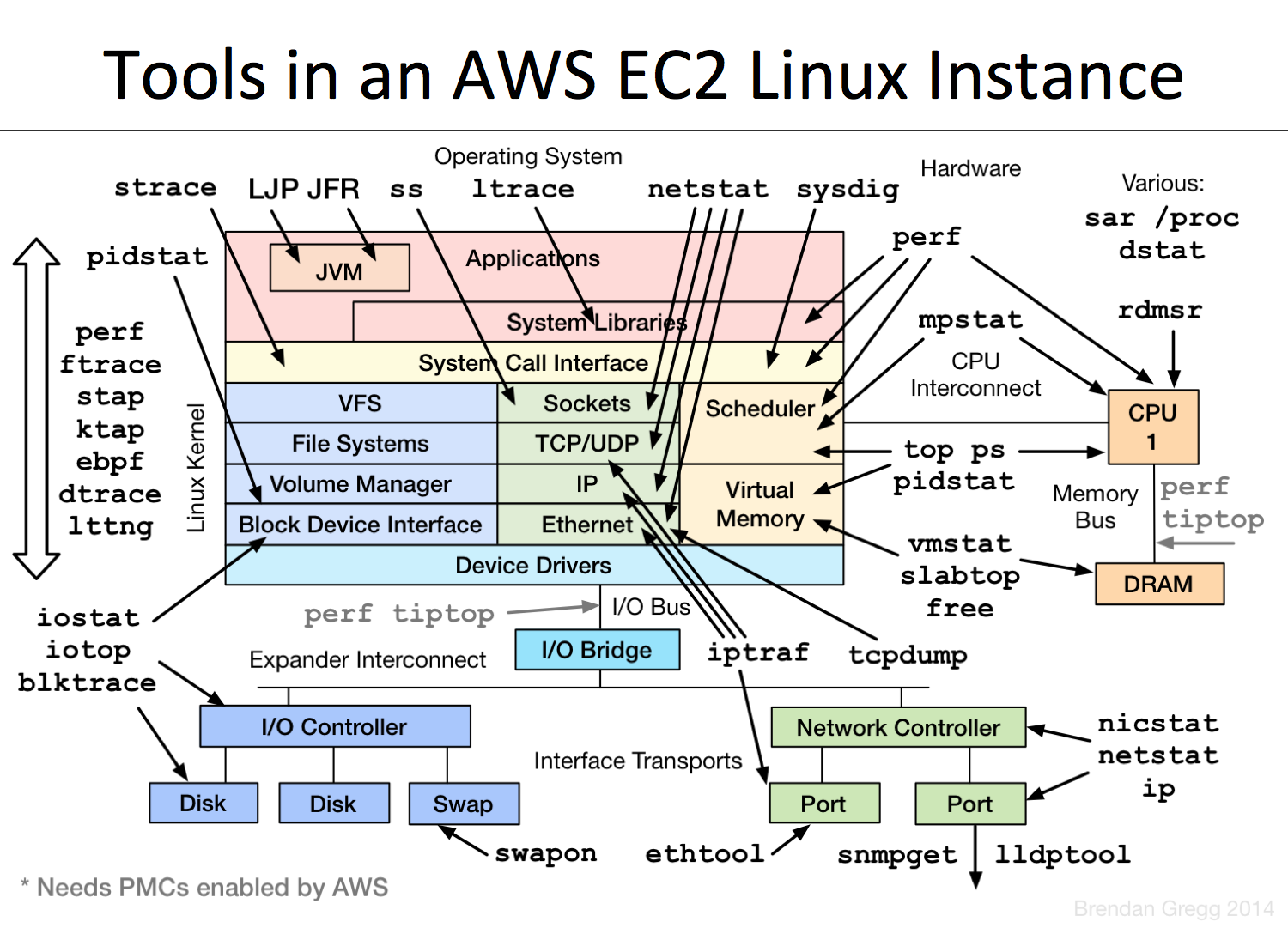
People liked the talk, although it surprised some. One comment was "it didn't feel like a Brendan talk". Yes, I've expanded my scope at Netflix, and I'm working on higher-level analysis now, not just low-level performance tools. It's exciting for me, and I feel I have a better and more balanced view of performance analysis, which I captured in this talk.
Keep in mind that you aren't necessarily expected to do the low-level performance analysis yourself. I summarized the likely real scenarios at the end of the talk:
- A. Your company has one or more people who do advanced perf analysis (perf team). Ask them to do it.
- B. You actually are that person. Do it.
- C. You buy a product that does it. Ask them to add low-level capabilities.
Perhaps the most valuable take-away of this talk is that you be aware that such low-level analysis is possible, so that if you are in situation (A) or (C), you can ask for it. I've found that performance monitoring companies often build products based on what customers think they want. However, what customers think they want is bounded by what they know is possible. You really want products that make low-level analysis easy, including flame graphs and latency heat maps. Some monitoring products already provide these (eg, Circonus, AppNeta), and at Netflix we're building Vector.
Last year at Surge, I saw a great talk by Coburn Watson titled How Netflix Maximizes Scalability, Resilience, and Engineering Velocity in the Cloud, which I recommend. His relaxed style threw me at first: he's able to talk very casually about complex performance issues in distributed environments, because he actually understands them extremely well. This year, he's now my manager at Netflix, and he's also still hiring. Great at performance and want to work with both Coburn and myself? Let him know. :-)
For more about low level performance analysis tools, see my previous blog posts, and my perf-tools and msr-cloud-tools collections on github.
Click here for Disqus comments (ad supported).